Data as a Product in the Age of AI
Hard-Won Lessons from the Frontlines of Intelligent Systems
I once watched an AI initiative fall apart before it ever left the POC.
The models were fine. The engineering team was sharp and experienced and leadership was excited - I mean AI, the buzzword of all buzzwords.
The problem?
No one trusted the data feeding the model — and worse, no one owned it.
I still remember the moment the team realized it. We were in a “go/no-go” meeting, and the VP of Product asked a simple question:
“If this model makes a decision we disagree with, where does the data behind it come from?”
Silence. Then a scramble of spreadsheets, lineage diagrams, and half-remembered SQL queries.
The truth hit hard: we hadn’t built a product. We’d built a science experiment.
That moment shaped how I think about every data and AI system since. Because no amount of modeling or prompt engineering can save you from poor data product thinking.
Thanks for reading! Subscribe for free to receive new posts and support my work.
🚨 Why AI Fails: When Data Isn’t a Product
I’ve seen it more times than I care to admit — companies racing to “do AI” while their foundation is crumbling underneath them.
They’ve got:
Dozens of dashboards, none of which agree
Pipelines owned by no one (or everyone)
KPIs built on one-off SQL extracts
“Data scientists” manually fixing upstream issues every week

And then they wonder why their generative AI pilots hallucinate, their ML models drift, and their “AI-driven insights” never make it past PowerPoint.
Here’s the uncomfortable truth:
AI doesn’t fix data problems. It exposes them.
When you treat data like a byproduct instead of a product, AI becomes a mirror — and it will reflect every flaw back to you, at scale.
🎧 Case Study #1: Spotify and the Power of Data Mesh
Spotify’s evolution toward a data mesh wasn’t about architecture — it was about accountability.
A few years ago, their central data team was the bottleneck. Every new dataset request came through the same funnel, and analysts across 100+ squads were waiting weeks to get what they needed.
So Spotify flipped the model:
Each squad became a data owner for its domain (playlists, artists, ads, engagement).
They published their data as products — versioned, discoverable, and documented.
The central data platform team focused on tooling, quality frameworks, and discovery layers.
What changed?
Speed — but more importantly, trust.
By distributing ownership but standardizing expectations, Spotify created a culture where every team could innovate independently without compromising integrity.
“We stopped chasing data. It started showing up where it needed to.”
That’s the essence of treating data as a product: it moves from being delivered to being discoverable.
🚗 Case Study #2: Uber’s ML Platform Evolution
Uber’s data challenges were legendary. Early machine learning experiments ran on top of brittle pipelines, inconsistent features, and ad-hoc datasets.
The breakthrough came when they built Michelangelo — their internal ML platform that reimagined how models consumed data.
They realized data for ML isn’t just input — it’s infrastructure.
So they standardized feature storage, automated lineage tracking, and treated every feature as a data product with its own lifecycle: creation → validation → versioning → deprecation.
That shift unlocked reliability and reuse.
Teams could now share features across models — not reinvent them.
Michelangelo wasn’t just a platform. It was a data product ecosystem, built to ensure that no AI model stood on unverified ground.
🧨 Case Study #3: The Cautionary Tale
One global retailer I worked with invested millions into a customer “AI personalization engine.”
They had a top-tier data science team, a sleek UI, and C-suite sponsorship.
But the project tanked. Why?
The customer data had no consistent schema across regions.
The source systems didn’t match the definitions used in the training data.
The feedback loops (clicks, purchases, etc.) weren’t captured in real-time.
The model was technically impressive — but operationally blind.
“You can’t personalize experiences on data that doesn’t know who the customer is.”
That’s what happens when you build an AI initiative without treating data like a product. You might ship something — but it won’t last.
🧩 What “Data as a Product” Really Means
Let’s strip away the buzzwords.
When I say “data as a product,” I mean this:
Data has a defined purpose, a clear owner, a measurable value, and an intentional lifecycle.
A data product isn’t a pipeline or a table — it’s a unit of trust and usability.
And just like any product, it needs:
A customer (internal or external)
A problem it solves
A definition of done
Metrics for success
Support and iteration
Netflix’s Data as a Product blog captured this perfectly: every dataset, no matter how technical, is designed to enable decisions.
In practice, that means versioning, SLAs, observability, discoverability, and feedback loops.
If your data team can’t answer “who uses this, why, and how it’s measured,” you don’t have a data product — you have a data dump.
⚠️ The Anti-Patterns: How Teams Get It Wrong
I’ve seen the same mistakes play out over and over again:
1. Treating Dashboards as Products
Dashboards are interfaces, not products. They sit on top of data products — but they’re not the foundation.
If you build governance around dashboards, you’re managing symptoms, not causes.
2. Ignoring Feedback Loops
Data consumers (analysts, PMs, AI engineers) are your users.
If you’re not collecting feedback, you’re shipping blind.
3. Focusing on Volume Instead of Value
More pipelines ≠ more insight.
Measure the impact of your data products, not their count.
4. Skipping Metadata and Documentation
If your data product doesn’t come with a schema, lineage, and sample queries, it’s not a product. It’s technical debt waiting to happen.
📈 What Great Data Product Teams Measure
Mature data product teams think beyond uptime and freshness.
They measure adoption, trust, and business value.
Key metrics I’ve seen work:
Adoption Metrics: Track how many unique users or teams access your data, how often it’s queried, and whether it’s being reused across domains.
Quality Metrics: Measure failed data checks, adherence to SLAs, and the rate of schema or pipeline issues detected.
Value Metrics: Quantify impact — for example, how much faster decisions are made or how much model accuracy improves.
Trust Metrics: Monitor data certification rates, lineage completeness, and how quickly issues are resolved once reported.
If you’re not tracking adoption and trust, you’re managing a pipeline — not a product.
“If you’re not measuring adoption and trust, you’re not managing a product. You’re maintaining a pipeline.”
🪜 Data Product Maturity Model
Here’s the five-level model I use when assessing an organization’s maturity:
Level 1 – Reactive:
Data is manually pulled, inconsistent, and frequently rebuilt. Analysts spend more time fixing data than using it.
Level 2 – Organized:
A central data warehouse exists, but ownership is unclear and SLAs are rare. Teams align on dashboards, but definitions vary.
Level 3 – Standardized:
Data catalogs, ownership, and basic quality checks are in place. Teams share consistent metrics and reusable models.
Level 4 – Productized:
Each domain owns versioned, discoverable data products with clear contracts, APIs, and adoption metrics. Governance becomes proactive.
Level 5 – Intelligent:
Data governance is autonomous. Observability is AI-driven. Pipelines self-heal, and data evolves dynamically based on usage.
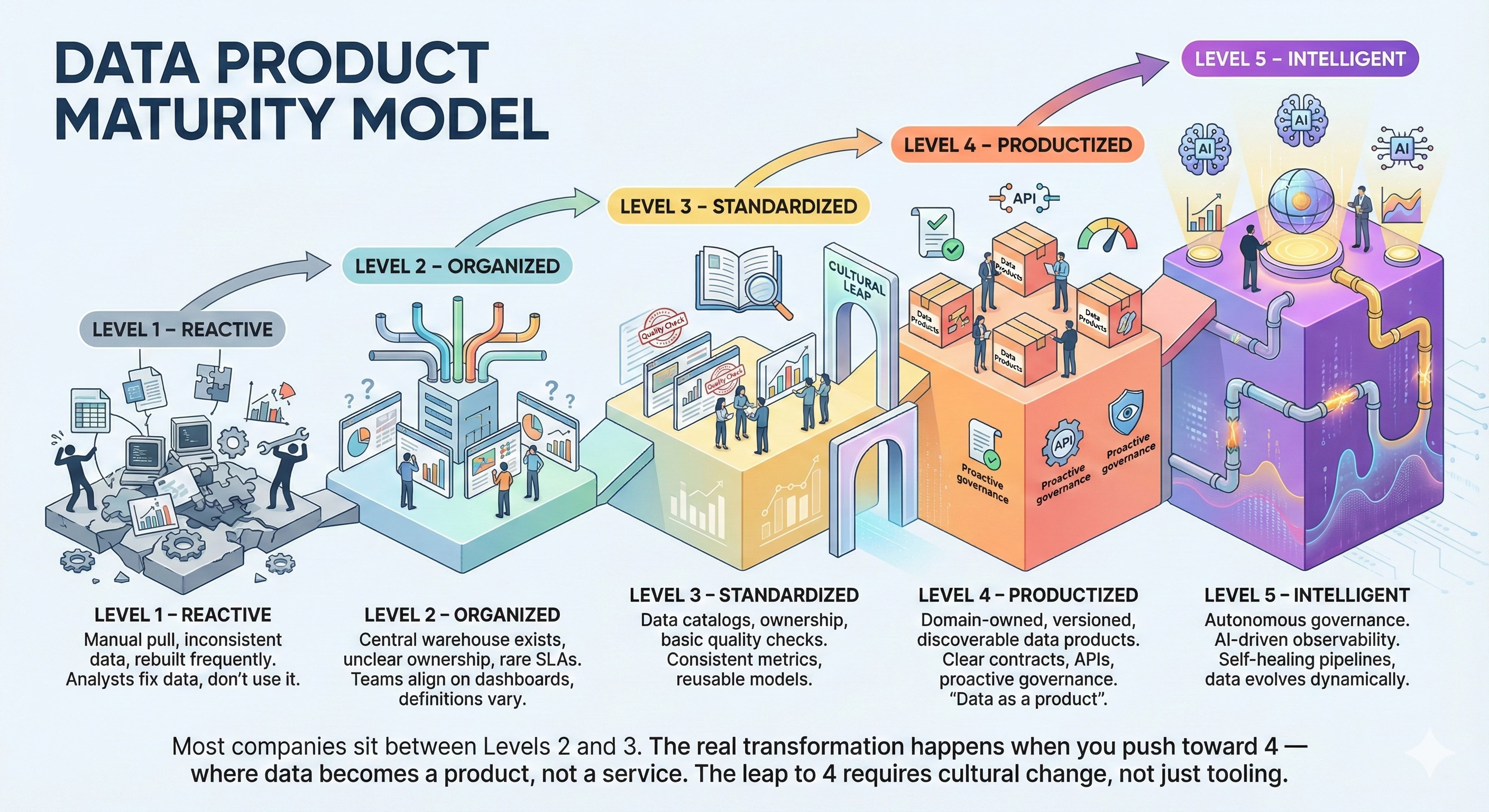
Most companies sit between Levels 2 and 3. The real transformation happens when you push toward 4 — where data becomes a product, not a service
The leap to 4 requires cultural change, not just tooling.
🔀 Decision Tree: Is It a Data Product or a One-Off?
Ask yourself:
Is it reused by more than one team? → Treat it as a data product.
Does it support a recurring decision or model? → Data product.
Is it highly specific to a one-time business question? → One-off analysis.
Does it require governance, lineage, or SLAs? → Data product.
If you can’t decide, default to building it as a data product — because future reuse always comes faster than you expect.
🧱 The Architecture: Foundations That Scale
Treating data as a product isn’t just cultural — it’s architectural.
Here’s what I’ve seen work:
1. Medallion Architecture (Bronze → Silver → Gold)
Bronze: raw ingestion (Fivetran, Airbyte)
Silver: cleaned and standardized (dbt, Databricks)
Gold: business-ready semantic models (Snowflake, Sigma, Tableau Cloud)
Each layer represents a stage of productization.
2. Semantic Layers & Data Contracts
Define metrics once, expose them everywhere.
Use dbt Metrics Layer, Transform, or AtScale for semantics, and enforce data contracts to prevent breaking changes.
3. Data Mesh vs. Data Fabric
Forget the debates — you need both.
Mesh = organizational ownership and domain autonomy
Fabric = unified governance, metadata, and policy enforcement
“Mesh defines who owns the data. Fabric defines how it flows.”
🤖 How LLMs Change the Game
The AI boom adds a new layer of complexity: context.
LLMs aren’t just consumers of data — they’re interpreters.
And that means data products now have to support:
Vectorization (embeddings, metadata enrichment)
Retrieval-Augmented Generation (RAG)
Fine-tuning pipelines
If your data products don’t have clear semantics, lineage, and documentation, your LLM will hallucinate — confidently.
I’ve seen teams feed unstructured customer notes into an LLM without proper cleansing or entity linking. The result? The bot fabricated entire support histories.
“LLMs don’t lie — they improvise on bad data.”
For generative AI, your data products are your guardrails.
For fine-tuning: ensure data consistency and representativeness.
For RAG: focus on relevance, recency, and retrieval latency.
For prompting: expose structured metadata so AI can reason contextually.
And yes — vector databases (like Pinecone, Chroma, Weaviate) are the new frontier of data product design. They extend the definition of what a data product is.
🔮 Looking Ahead: What’s Next (2025–2026)
Here’s where I see the next two years going:
1. Semantic Layer Engineers Will Be in Demand
The role that bridges business meaning and machine understanding.
Think of them as translators between AI and data.
2. AI Data Stewards Will Replace Traditional Governance
Instead of gatekeepers, they’ll be facilitators — using AI-driven policy automation to manage access dynamically.
3. Synthetic Data Becomes Strategic
As privacy laws tighten, synthetic data will power model training and testing safely — but it’ll only be as good as the data products it mimics.
“Tomorrow’s most valuable data may never have existed in the real world — but it’ll still need governance.”
🧭 The First 90 Days as a Data Product Leader
If you’re stepping into a new org or trying to mature your current one, here’s how I approach it:
Days 1–30: Diagnose
Map your data ecosystem: who owns what, where it lives, and how it flows
Identify your top 5 critical data products
Audit SLAs, contracts, and adoption
Days 31–60: Design
Build your Data Product Maturity Map
Define ownership and contracts for each critical data product
Launch a “Data Product Review” cadence — monthly reviews for product health
Days 61–90: Deliver
Pilot one end-to-end data product lifecycle (from request → delivery → adoption)
Implement feedback loops and usage analytics
Publish internal documentation and metrics
“The first 90 days aren’t about dashboards — they’re about decisions.”
🧠 Interview Questions to Gauge Maturity
When evaluating a company’s data maturity, I ask:
How do you measure trust in your data?
Who owns data quality — the platform team or the business?
What’s your process for deprecating unused datasets?
How do AI initiatives consume and validate data?
How do you measure the success of a data product?
If the answers are vague, the maturity is too.
📚 Reading List & Communities
If you’re diving deeper, here’s where I’d start:
Netflix Tech Blog: Data as a Product
Martin Fowler: Data Mesh Principles & Logical Architecture
Thoughtworks Technology Radar (2024): Data Mesh and Fabric Trends
Data Council Talks (2024): Building Data Products for AI
dbt Slack & Coalesce Conference Talks
LinkedIn Groups: Data Product Management Alliance
💡 Final Takeaways
After years in the trenches, here’s what I’ve learned the hard way:
Data products aren’t born — they’re designed.
AI doesn’t create value. It scales it.
If your data team isn’t measuring adoption, it’s not managing products.
Governance isn’t control — it’s enablement.
Data as a Product isn’t a framework. It’s a leadership mindset.
“The best data platforms don’t deliver reports. They deliver trust.”
So as you plan your next AI initiative, ask yourself one question:
Is your data powering intelligence — or improvisation?
Because in the age of AI, that answer determines everything.